
Дослідники з Rice University, Johns Hopkins University та Nvidia представили новий підхід до навчання мультимодальних ШІ, використовуючи прості аркадні ігри замість спеціалізованих математичних наборів даних. Вони розробили метод «Visual Game Learning» на основі моделі Qwen2.5-VL-7B, де ШІ тренується, граючи у варіанти ігор Snake і Tetris.
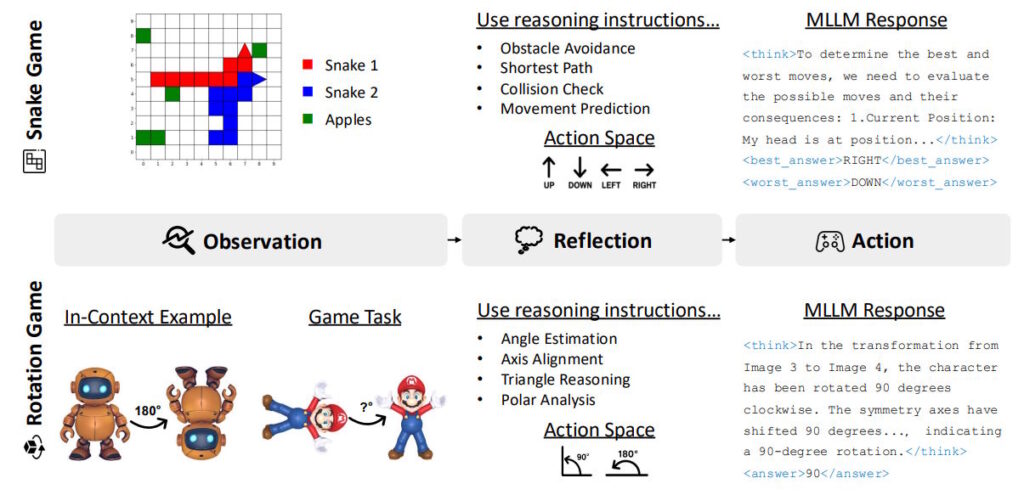
Для кожної гри дослідники створили 36 тисяч навчальних прикладів із різним рівнем складності. Тренування на Snake покращило здатність моделі вирішувати задачі з координатами та виразами, а навчання на грі з обертанням підвищило точність у визначенні кутів і довжин. При цьому для 3D-об’єктів використовували Hunyuan3D як джерело даних. Після такого навчання модель краще орієнтується у просторових задачах і демонструє покращені навички планування ходів.
Результати тестування показали, що модель, навчена на іграх, досягла точності 50,6 відсотка на математичних бенчмарках, обігнавши спеціалізовану модель MM-Eureka-Qwen-7B, яка показала 50,1 відсотка. Особливо помітний прогрес був у задачах з геометрії, де показники майже подвоїлися. На загальних тестах ViGaL отримала 53,9 відсотка, що вище за GPT-4o, але трохи поступається Gemini 2.0 Flash.

Після навчання на іграх модель перевірили на класичних Atari-іграх, таких як Breakout і Ms. Pac-Man, а також на різних завданнях з математики, геометрії і аналізу 3D-сцен. Тут ViGaL суттєво перевищила базову версію моделі за результатами. Дослідники відзначили, що підказки крок за кроком і спеціальний підбір винагород у процесі навчання підвищили точність ще на кілька відсотків.
Використання підходу з підкріпленням дало приріст продуктивності на 12,3 відсотка, тоді як стандартне донавчання зменшило точність. Збільшення обсягу даних також позитивно вплинуло на результати. Дослідники вважають, що подібні ігрові середовища можуть стати ефективним способом навчання ШІ для розвитку загальних навичок міркування.









