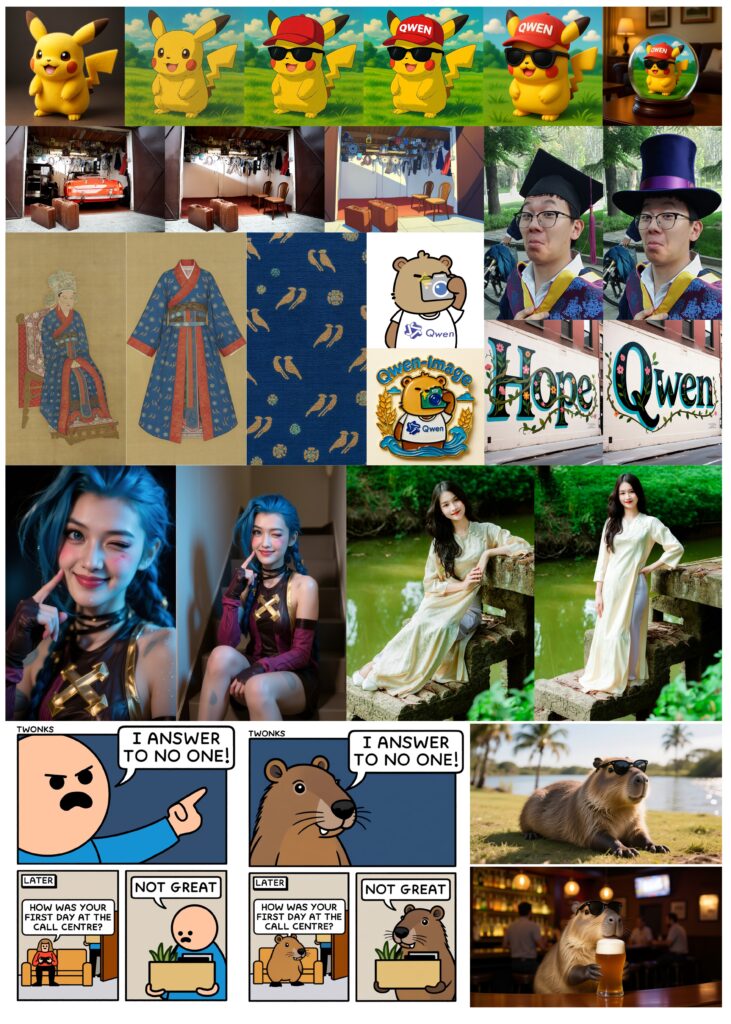
Alibaba представила Qwen-Image — нову ШІ-модель з 20 мільярдами параметрів, яка створює зображення з високоякісним текстом у різноманітних стилях. Розробники зазначають , що Qwen-Image підтримує двомовний текст і легко перемикається між мовами, а також генерує текст у різних візуальних контекстах — від вуличних сцен до слайдів презентацій.
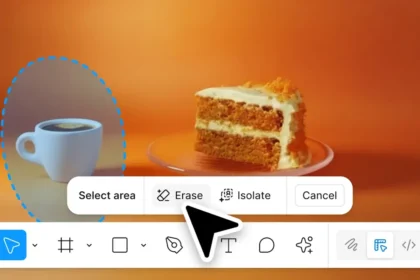
Модель дозволяє не лише створювати нові зображення, а й редагувати їх — змінювати стиль, додавати або видаляти об’єкти, а також коригувати пози людей на фото. Qwen-Image виконує завдання класичного комп’ютерного зору, наприклад, оцінює глибину зображення чи створює нові ракурси, зберігаючи оригінальний зміст.
Архітектура Qwen-Image включає три основні компоненти: Qwen2.5-VL для розуміння тексту й зображень, Variational AutoEncoder для стискання зображень і Multimodal Diffusion Transformer для створення фінального результату. Нова технологія MSRoPE забезпечує точне розміщення тексту в зображеннях, що підвищує якість поєднання тексту й картинки навіть за різних роздільностей.

Команда Alibaba побудувала навчальний набір даних без використання ШІ-згенерованого контенту, зосередившись на фотографіях природи, дизайні, зображеннях людей та синтетичних прикладах. Додаткові фільтри відсіюють зображення низької якості, а різні підходи до рендерингу тексту забезпечують різноманітність даних для навчання.
У тестах Qwen-Image обійшла кілька комерційних моделей, таких як GPT-Image-1 і Flux.1, особливо у створенні та редагуванні зображень, а також у точності рендерингу китайських символів. Модель доступна безкоштовно на GitHub і Hugging Face, а користувачі можуть протестувати її в живій демонстрації .