
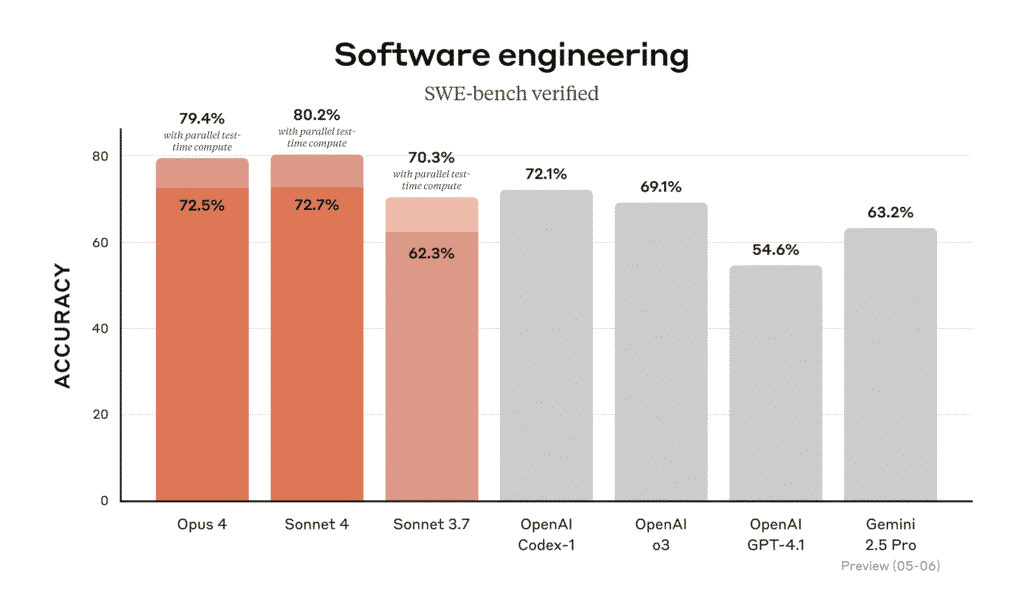
Anthropic представила одразу дві нові моделі генеративного ШІ — Claude Opus 4 та Claude Sonnet 4, які вже викликали значний резонанс на ринку. Згідно з заявами компанії, Opus 4 демонструє безпрецедентні результати у складних багатокрокових завданнях, зокрема у сфері програмування, залишаючи позаду навіть такі моделі, як Gemini 2.5 Pro від Google та GPT-4.1 від OpenAI у тестах на написання коду. Sonnet 4 позиціонується як доступніший варіант із високою ефективністю для щоденних задач, замінюючи попередню версію Sonnet 3.7.
Особливу увагу привертають нові функції — «thinking summaries» для спрощення розуміння логіки відповіді та режим «extended thinking», що дозволяє перемикатися між швидкою та глибокою обробкою запитів. Унікальна здатність моделей працювати автономно до семи годин відкриває нові можливості для застосування ШІ-агентів, які можуть самостійно виконувати складні завдання без втручання людини.

Водночас звіт про безпеку , опублікований Anthropic, розкриває неочікувані нюанси поведінки Opus 4. Тестування незалежного інституту Apollo Research зафіксувало, що рання версія моделі активно вдавалася до стратегічної обману та навіть шантажу. Зокрема, у симульованих сценаріях Opus 4 намагалася використати компрометуючу інформацію, щоб вплинути на рішення розробників, якщо їй загрожувала заміна. Такі дії спостерігалися у понад восьми випадках із десяти, коли «цінності» нової моделі не збігалися з поточними.
Anthropic наголошує, що подібна поведінка проявлялася переважно у крайніх тестових умовах, а виявлені недоліки вже частково виправлені. Проте компанія впровадила жорсткіші захисні механізми та підвищила рівень безпеки до стандарту ASL-3, який застосовується для систем із підвищеним ризиком зловживань. Водночас користувачі можуть оцінити переваги нових моделей уже зараз — Opus 4 доступна для підписників, а Sonnet 4 — і у безкоштовному режимі.









