
Google представила нову функцію для своєї моделі ШІ Gemini 2.5, яка дозволяє виділяти та аналізувати частини зображень за допомогою звичайних текстових запитів. Тепер користувачі можуть звертатись до моделі природною мовою і отримувати відповідь, яка враховує складні запити, наприклад «людина з парасолькою» або «всі, хто не сидить». Gemini розпізнає не лише чіткі об’єкти, а й абстрактні поняття, такі як «безлад» чи «пошкодження», а також може знаходити елементи за текстом на зображенні.
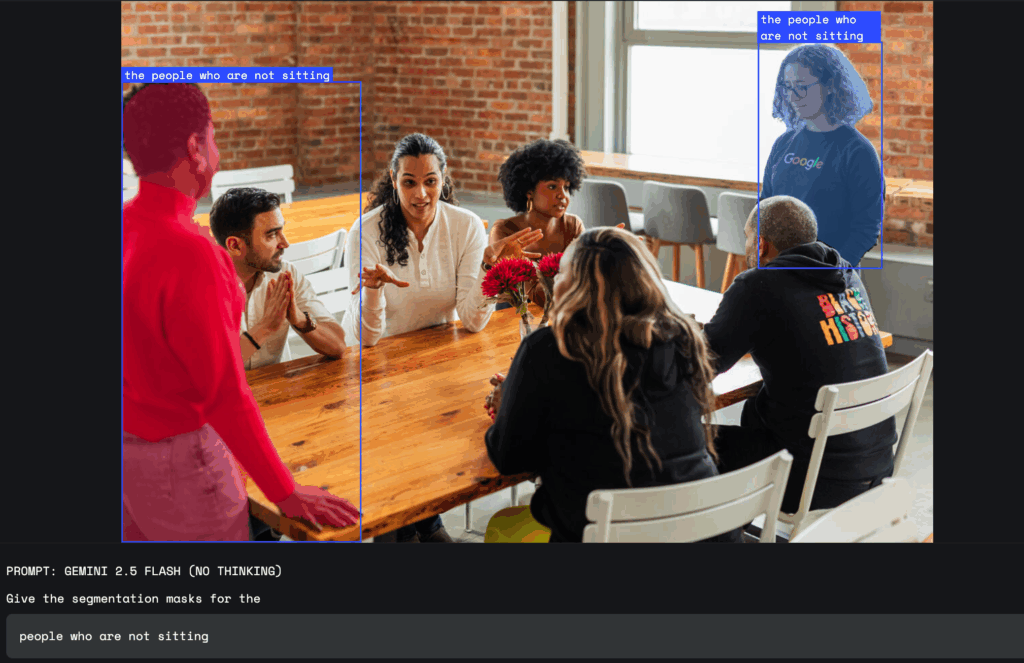
Функція підтримує багатомовні запити та може давати підписи до об’єктів іншими мовами. Користувачі отримують результат у вигляді координат обраної області, маски пікселів і підпису, що дозволяє швидко визначити потрібну частину зображення. Для цього не потрібно використовувати окремі інструменти чи моделі, оскільки все обробляє сама модель Gemini.

Розробники мають доступ до нової можливості через Gemini API. Google рекомендує для найкращої роботи використовувати модель «gemini-2.5-flash» і встановити параметр «thinkingBudget» на нуль для миттєвої відповіді. Перші випробування можна проводити у Google AI Studio або через Python Colab.
Функція стане у пригоді дизайнерам, які тепер можуть виділяти деталі на фото простими командами, наприклад «виділити тінь будівлі». У сфері безпеки праці Gemini допоможе знаходити порушення, наприклад «усі люди на будівельному майданчику без шолома». В страхуванні ця можливість дозволяє автоматично позначати пошкоджені будівлі на аерофотознімках, що економить час під час оцінки збитків.









